近期,中國科學院合肥物質院智能所謝成軍與張潔團隊將多模態融合方法應用于遙感圖像全色銳化領域,相關研究成果以“Exploring Text-Guided Information Fusion Through Chain-of-Reasoning for Pansharpening”為題發表在地球科學和遙感領域的中國科學院一區Top期刊IEEE Transactions on Geoscience and Remote Sensing (IEEE TGRS)上。
遙感圖像全色銳化技術旨在融合低分辨率的多光譜(LRMS)圖像與高分辨率的全色(PAN)圖像,以生成兼具高空間分辨率和豐富光譜信息的遙感影像。盡管由文本引導的多模態學習方法在自然圖像領域已經取得了顯著進展,但由于全色銳化領域多模態數據集的缺乏,以及遙感場景的復雜性等問題,為語義信息的準確提取帶來了巨大挑戰。
為解決上述挑戰,研究團隊提出了一種創新的文本引導多模態融合框架(TMMFNet)。該框架首先基于多模態大語言模型(MLLMs),結合超分辨率模型、地理空間分割模型以及思維鏈(CoT)提示技術,為LRMS圖像生成高質量的語義描述文本,從而構建了面向全色銳化的多模態遙感數據集。此基礎上,團隊設計了文本增強模塊(TEB)與文本調制模塊(TMB)兩個核心融合單元,能夠將文本中所蘊含的高層語義信息有效注入融合網絡,從而引導并優化視覺特征的融合過程。在WorldView-II、GaoFen2和WorldView-III等多個公開衛星數據集上的實驗結果表明,所提方法在峰值信噪比(PSNR)和結構相似性(SSIM)等關鍵評價指標上均表現出優越性能。
碩士生李薛恒為論文第一作者,謝成軍研究員、張潔副研究員為論文通訊作者。該項工作得到了安徽省自然科學基金、合肥市自然科學基金項目的支持。
論文鏈接:https://ieeexplore.ieee.org/abstract/document/11145881
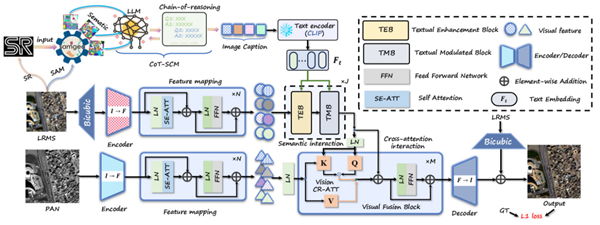
圖 1 基于視覺-文本多模態融合的遙感圖像全色銳化網絡
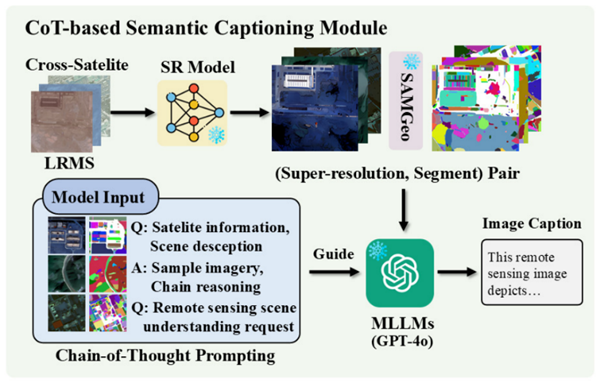
圖 2 多光譜影像語義描述生成方法
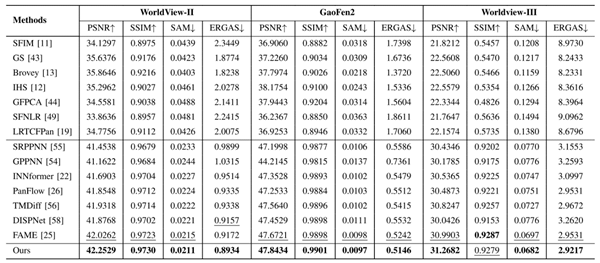
表1 模型在不同數據集下的實驗結果

圖 3 不同全色銳化模型在WorldView-II數據集上的實驗結果比較




